現代中国語の発展パシフィックエンジニアリング 中国室言語グループ編(文責:亀島)Copyright (C) 1999-2012 Pacific Engineering Co. All Rights Reserved. 補足A3. 漢字の近現代史
漢字は、最近数十年で中国の漢字簡化や日本の常用漢字化など大きな変化を経験している。 本稿では、 漢字の歴史のうち「ごく最近」とも言える近代以降に焦点を当てて略述したい。
前史 - 近代以前 漢字の歴史は3000年以上に及ぶ。その漢字の長大な歴史のうちで、 金属製の活字書体が作られるようになってから、さして時間はたっていない。ましてやコンピュータでコード化されるようになったのは、ごく最近の話である。
漢字の表現媒体として大部分の期間にわたって使われてきたのは、 手書きおよび木版印刷という手段である。 この過程で、 多数の略字や異体字が生み出された。 清初の康熙年間、西暦でいえば18世紀の前半、「康熙字典(こうきじてん、 Kangxi Zidian)」が編纂されたが、 この時点で 4万数千の文字が「漢字」と認定され辞書に収録された。 もちろん、 日常に使われていた漢字はせいぜい数千字、 4万数千字の大部分は古書にしか見られない文字や略字や異体字であった。 たとえば「群」の異体字として「羣」や「島」の異体字として「嶋」、「嶌」など数個の異体が収録されている。 康熙字典ではこれらの異体のうち、 一部を「正字」として定め、 他を「俗字」、「古字」などとした。 康熙字典は、 以後の漢字の権威となるが、 「群」を俗字、 「羣」を正字と定めるなど、ここで定められた「正字」が、現代中国や日本で「正しい」とされている文字とは限らない。 康熙字典が作られたのは200年も前のことだから、 漢字の規範が時代とともに変わるのは無理もない。 また、言葉が生き物である以上、権威になる辞書が存在するからといって、異体字、俗字の新造が止まるはずがない。 事実、現代に至るまで多数の「新字」が生み出され続けている。 中国・日本・朝鮮などの漢字圏では、 このような情況の中で近代化の時期を迎えることになる。 この時期までは、 日本などで独自の文字(日本で作られた「辻」、「峠」などの「国字」、 朝鮮半島の「吏読文字」、ベトナムの「字喃」など同種のものが各国にある)が少数作られたほかは、漢字圏のすべての国で共通の漢字が使われていたと言ってよい。 もちろん、 今日見られるような「簡体字」、「繁体字」などの区別はない。 国ごとの差異は少ないが、 それぞれの国で使われている漢字には、 手書き文字の字形差に由来する大量の異体字が存在した。 異体字の整理 - 活字印刷と近代教育制度 19世紀後半以降の近代化の中で、 活字印刷が一般的になった結果、 異体字は急速に減少していった。 なぜなら、手書き文書の場合は、 好みによって複数の異体字が使い分けることができるが、 活字の場合は、意味に差のない異体字をわざわざ新鋳するのは経費や労力がかかりすぎ、とても計算が合わないからである。したがって、異体字を整理して最もよく使われる字体に統合しようとする傾向が強くなっていった。
余談になるが、 日本語のひらがなにも多数の異体字(「変体かな」とよばれる)が含まれていた。 明治初年以降活字印刷の普及とともに急速に整理され、 明治10年代の印刷物は、現代のひらがなとほぼ変わらない字形が使用されている。 近代化とともに開始された国家による教育制度の整備も、 異体字の整理に大きな役割を果たした。 近代以前の寺子屋に代表される私塾形式の教育制度から、 国家的に統一教材を用いた近代教育制度に変わったことによって、 国家的な規模で異体字の統一が実現したのである。 反面、この時期から中国・日本・朝鮮などの漢字圏で使われている漢字に国別の差異が生じた始めた。 筆順などで各国の差が見られるようになったほか*1、 複数の異体字のうち、どの文字を「正式」の文字と規定するかによって、たとえば「兎」と「兔」などの漢字に、国別に微妙な違いが生じた*2。 しかし、 各国とも基本的には、康熙字典に由来する文字を採用したので、 この時期には字形の差はさほど大きくない。 中国語圏で「繁体字」、 日本で「旧字体」や「正字」などと呼ばれている漢字がほぼ確定し、 第二次世界大戦後の文字改革に至るまで安定して使われ続けることになる。 1*元来、筆順に関する「権威」的な規定は存在しない。 統一的な筆順は、各国の政府・教育機関によって近代になってから定められた近代教育制度の産物である。 国別に相当の差異があると同時に、現代に至っても学校教育と書道師範で違う筆順を教えていることも多い。余談であるが、日本の小学校教育で「左」と「右」の筆順が違うなどは、日本独自の教育法に過ぎず、漢字圏では特異である。 2*異体字のほか、活字鋳造の過程で微妙な国別の書体差が発生し、のちに漢字コードを定めるときに問題になった。 漢字の現代史 - 漢字簡化と常用漢字化 第二次世界大戦後、 日本と中国大陸で漢字改革が行われた。 漢字の字形を大幅に簡単にしながら漢字の種類を減らそうとする試みである。あらためていうまでもないが、その目的は、 漢字学習の負担を軽くし、 識字率を向上させることなどにあった。
1949年の日本の「当用漢字」、 1954年に中国大陸で公布された「漢字簡化方案」が、その典型だった。このときは、かつてないくらい、大胆な漢字の簡易化が行われた。 台湾や香港などの中国政府の影響が及ばなかった地域、ならびに朝鮮半島では、 政府主導の漢字簡易化は行われず、 「繁体字」が現在に至るまで使われている。 その結果、中国大陸の「簡体字」と日本の当用漢字(現在の呼称に従って「常用漢字」とする)および台湾・香港・韓国などを中心とする地域で使われている「繁体字」の区別が生じた。 漢字の簡易化は、 日本・中国でそれぞれ独立して行われたが、漢字という文字の構造が同じである以上、 手法は共通せざるをえなかった。簡易化の手法としては、 おおむね以下にあげる原則が採用されている。 1.漢字の筆画を減らす 複雑な漢字の筆画を減らし、 簡単な字形にする。 新たな字形を作ることもあるが、 多くの場合は、 異体字や草書体由来の略字の中で、筆画の少ない文字を選ぶ方法である。 たとえば、中国の簡化漢字「个」は古くから使われている「箇」、「個」の異体字で、 日本語の「ヶ」(「千駄ヶ谷」、「一ヶ所」のなどの「ヶ」)と同じ文字。 日本の常用漢字「礼」は「禮」の古字とされている文字である。
どちらも筆画の簡単な異体字を正式な文字として採用したもので、 近代化の中で整理排除されていた異体字を正式の文字に昇格させたものと言える。 旁偏のみの省略もこれに準じて考えることができる。 2.漢字の種類を減らす 漢字を本来の意味と違う意味で通用させる。 従来「誤用」とされていた用字法を正式のものとして承認する方法や、 当て字に類する方法が大胆に採用された。 たとえば、 中国では「製」や「幹」の字を排除して、それぞれ「制」や「干」で置き換えた。 「製造」、 「幹部」が中国大陸ではそれぞれ「制造」、 「干部」になる。 「制」も「干」も古くからある漢字だが、 漢字改革の結果、 全然別の意味に用いられるようになった。 日本でも漢字数を減らすため、 同音字を使った大胆な置き換えが進められた。 たとえば、 「亢奮(こうふん)」は「興奮」に、 「遵法(じゅんぽう)」は「順法」に置き換えられた。「輿論(よろん)」を置き換えたはずの「世論」が「せろん」という別の単語になってしまった例もある。
漢字改革の結果、 漢字学習の容易さ、 漢字の読みやすさは格段に向上したが、 漢字の国際的な通用性は低下した。 たとえば、 日本語の常用漢字は一般に中国で通用しない。 もしあなたが日本人で中国などの漢字圏の人と筆談を試みるなら、 旧字体(繁体字)の使用をおすすめする。 日本の常用漢字よりは通用性が高い。 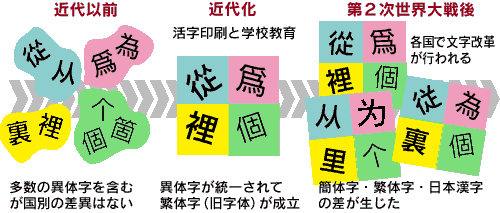
漢字コード - 漢字のコンピュータ化 コンピュータで扱えるのは文字コードだけである。そのため、コンピュータの発達とともに漢字をコード化する必要が生じた。 異なったコンピュータ間でデータの互換性を保証するため統一した文字コードが求められるので、 文字コードの制定は国家レベルのプロジェクトとなった。
1980年代には、 日本・中国・台湾などで漢字コードに関する国家レベルの規格が制定された。 日本ではJISコード、 中国大陸ではGBコード、 台湾ではBIG5コードが制定後何度かの改定を経ながら、 現在までの主流となっている。 国家レベルでの漢字コード制定 これらの漢字コードは、 各国で常用されている漢字について各国が独自に定めたもので、 当然ながら、 それぞれのコードに互換性はない。 たとえば、 JISコードで書かれた漢字文字列をGBコードに完全に変換することは一般には不可能である。
また、 これらの漢字コードは国別に定められたものなので、 各国の文字に固有のコードだ。 JISコードは日本の常用漢字用、 GBコードは中国大陸の簡体字用となっている。 (JISコードには相当数の旧字体が含まれているが、 これは人名などの固有名詞によく使われる文字を収録したもので、 網羅的ではない。) 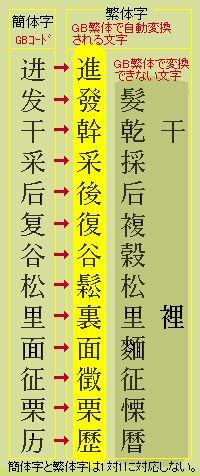
唯一の例外、「繁体GB」 国家レベルの漢字コードは、その国で使われている漢字に固有のものである。 この原則に対する唯一の例外がGBコードである。 通常のGBコード(GB2310)のほかに「繁体GB」とでも言うべきGB12345-90(以下、「繁体GB」と呼称する)が定められている。 繁体GBでは、 GB2310の各簡体字と同じコードに相当する繁体字を割り当てられている。 たとえば、「体」のGBコード(GB2310)の4469は、繁体GB(GB12345-90)では繁体字の「體」である。
この「繁体GB」には便利な点がある。 GBコードで書かれた簡体字の文書を、 「繁体字フォント(GB12345-90準拠のフォント)」を使うだけで繁体字の文として読めるようにすることができる。 GBコードででは「体」の文字が、フォントを「繁体GB」に変えるだけで相当する繁体字「體」の文字になる。 原則として自国内では使われていない繁体字のために、わざわざ漢字コードを定めている。 「繁体GB」に寄りかかった「繁体字フォント」の問題点 ところが、この「繁体GB」には致命的な欠陥がある。この欠陥は、簡体字と繁体字が一対一に対応していないことに由来する。もう少し、詳しく説明しよう。
そもそもGBコードは、漢字の簡化が浸透していた中国大陸で制定されたコードである。ということは簡化された漢字、つまり簡体字の使用を前提にしているわけで、この簡体字が実は曲者である。 一個の簡体字に一個の繁体字がきちんと対応してくれていれば問題はない。しかし、現実には、1個の簡体字が複数の繁体字に対応している場合がけっこう多い。 「繁体GB」では複数ある繁体字のうち、1個にしか対応させることができない。 要するに、「繁体GB」は、あくまで便法か、一時しのぎの小手先芸にすぎないのである。 具体例を上げてみよう。 たとえば、簡体字の「干」は、繁体字の「干」・「幹」・「乾」の簡体字でもある。したがって、GBコード簡体字の「干燥」を繁体字にしようとすると、「乾燥」のはずが「幹燥」という間違った表示になる。 その他にも、おかしな例はいくらでもある。GBコード簡体字の「谷」は、繁体字の「谷」と「穀」の両方の簡体字なので、「穀物」のはずが「谷物」になってしまう。同じく、GBコード簡体字の「征」は、繁体字の「征」のみならず、「徴」の簡体字でもあるために、「征服」のはずが「徴服」になってしまう・・・・・。 「繁体字フォント」には注意が必要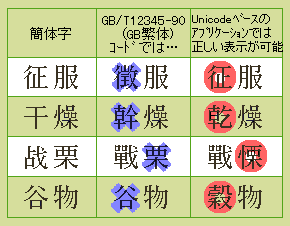
最近、日本語Windows上で動く中国語ソフトがいくつか発売されるようになっている。そのなかには、いかにも得意げに、「当社の製品は簡体字と繁体字の両方に対応します」と宣伝しているものもある。
しかし、「簡体字と繁体字の両方に対応」とはいっても、中国のGBコードだけに寄りかかっているために、簡体字と繁体字が一対一でしか対応していない製品も少なくない。たしかに、言葉の上では、「簡体字と繁体字の両方に対応」しているのかもしれない。だが、それは実際には極めて不十分な対応関係でしかなく、実用上は幼稚なレベルにとどまっているのである。 また、書体の数をやたらと誇示している製品があるが、肝心なのは書体の数ではなく、簡体字と繁体字に完璧に対応しているか否かである。この点について詳しい説明がない製品は、その実力を疑ってみたほうがいい。書体の数うんぬんなどは、いわば厚化粧の類にすぎず、そんなことばかり強調するような製品に限って、いちばん大事な部分が欠けていることが多い。 Unicodeの功罪 最後に話題のUnicodeについて説明しよう。 Unicodeは、世界中の言語で用いられているあらゆる文字に通し番号を付けて、コード化しようとする試みである。提唱したのは、 アメリカのコンピュータ・メーカーである。つまり、民間主導で制定されたコードで、この点は、 JISコードや GBコード・ BIG5コードなどように、国家レベルで制定された文字コードとは、 本質的に異なる。
Unicodeでは、言語と無関係に文字の形だけに着目して、コード化する手法が取られている。たとえば、日本語の漢数字の「一」も、中国語の「一」も、Unicodeでは4E00。 同一画面上に複数の言語が混在した文を表示させるには、非常に便利な方法である。 (しかし、Unicodeの全文字に対応するフォントは、一般的には入手できない。いまのところ、あくまでコンピュータの内部コードとして、利用される場合がほとんどである。) もっとも、 日本では、Unicodeは評判が良くない。その理由は、国や地域ごとに、漢字の字形が微妙に異なっている事実を無視して、同じものとして、扱っているからである。この点は、漢字を日常的に使うことのない欧米の研究者たちが、無神経に制定したという批判を免れない。一部の狂信的な民族主義者ならずとも、納得しかねる措置といってよい。 かつて康熙字典は、漢字はかくあるべきものとして、統一された字形を制定した。その背景にあったのは、一人の皇帝によって統一された世界、その世界にふさわしい統一された字形、という中華イデオロギーだった。 しかし、もはや現代は、康熙字典を生み出した中華帝国の時代ではない。各国で近代化が進行する過程において、漢字はそれぞれ自国語を表現するための文字として分化してきた。いいかえれば、 近代化が漢字を、「東アジア中国文化圏の共通文字」から「各国の国民文字」に変質させたのである。 したがって、中国語・日本・朝鮮半島などの漢字圏に、一律に適用される漢字コードを定めるのは、時代錯誤的な面がある。 一方、簡体字・繁体字・日本漢字を混在させ、微妙な字形の違いは問題にならないアプリケーションにとって、Unicodeは非常に便利である。(もちろん、字形で明瞭に区別できる「干」・「幹」・「乾」などには異なる文字コードが割り当てられているので、「繁体GB」のような問題は発生しない。) 実際問題として、華僑圏で流通している手書き文書を見ていると、繁体字・簡体字の混在が多い。華僑圏では、国家レベルで制定された字形が必ずしも絶対的な権威をもっているわけではなく、人々は自分達が使いやすい字形を自由に使っている。 これは、単なる過渡的な現象であろうか? 第三者の目からは、漢字が長い歴史をかけて培ってきた「国際性」に、華僑圏の人々は多分に依拠しているように見える。その意味からすれば、現在でも漢字は「アジアの共通文字」といってもあやまたない。つまるところ、 Unicodeの問題は、漢字文化の問題そのものである。 Unicodeは、1992年に至って ISO10641-1として規定され、「国際標準」とされることとなった。また、JISもこれを追認し、UnicodeをJIS X0221として、採用するに至っている。これらの事実を考慮するなら、少なくとも当分のあいだ、 Unicodeが文字コードの主流となるはずである。 「現代中国語とは?」の補足として本稿のほかに「A1. 現代中国語の成立小史」、 「A2. 中国語の表音方法 - ピンインと注音字母」、 「A4. 日本と中国の漢字音」、 「用語集」があります。
本稿に関するご意見は、webmaster@pacific-en.co.jpあてにお願いいたします。 |